
Table of Contents
Source: https://blog.griddynamics.com/retrieval-augmented-generation-llm/
In the previous post, we saw a basic introduction to the RAG. Now, let’s cover the next level details of the Retrieval Augmented Generation End to End Pipeline in this post
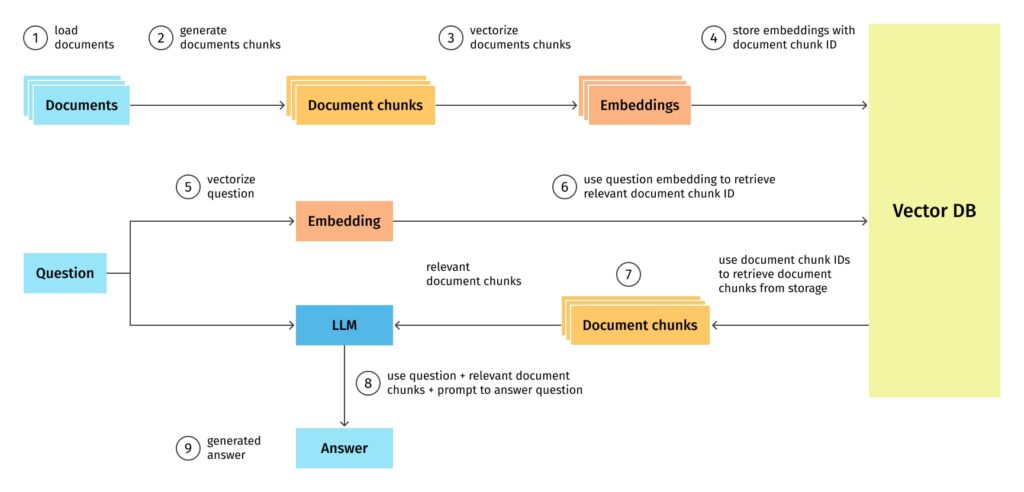
Below is an overview of an RAG system architecture.
1. Extract and Load the Documents from the User
Extraction
The first step in the RAG pipeline is to gather a wide array of documents covering a broad spectrum of knowledge. These documents could range from Wikipedia articles to books and scientific papers to web pages. The goal is to create a comprehensive database that the model can draw upon to find relevant information.
Extraction Options:
- Sources: Depending on the application, documents can be sourced from specific domains, e.g., scientific articles from PubMed for medical inquiries, legal documents from court databases for legal advice, or a mix of sources for general knowledge questions.
- APIs and Scraping: To automate the collection process, utilize APIs provided by content platforms (e.g., Wikipedia API) or web scraping tools (e.g., Beautiful Soup for Python).
Loading
Once the documents are collected, they must be processed and loaded into a format accessible to the retrieval system. This process often involves converting various document formats into a standardized form, ensuring that the text is clean (free from formatting issues, HTML tags, etc.), and segmenting documents into manageable parts if they are too long.
Loading Examples
- Format Standardization: Convert documents to a uniform format, such as JSON, with fields for title, content, and metadata. This simplifies processing and retrieval.
- Cleaning Tools: Use libraries like NLTK or spaCy in Python to clean and preprocess the text, removing unnecessary tokens and standardizing language for consistency.
2. Chunking and Considerations
Chunking
Documents, especially lengthy ones, must be broken down into smaller chunks to make the retrieval process more manageable and efficient. Depending on the document’s structure and content density, a chunk could be a paragraph, a section, or a subset of sentences.
Chunking Strategy
- Fixed-Length: Divide documents into fixed-size chunks, e.g., every 500 words. This is straightforward but might cut important information across chunks.
- Semantic Boundaries: Use natural document divisions, such as paragraphs or sections, which helps preserve context. Tools like spaCy can assist in identifying these boundaries.
Technical Considerations
- Overlap: Introduce overlap between chunks to ensure no loss of context around the boundaries. A common practice is to have a 50-word overlap.
- Chunk Indexing: Assign unique identifiers to each chunk, facilitating efficient retrieval and reference to the source document.
3. Vectorize the Document Chunks
Vectorization transforms the textual chunks into numerical representations (vectors) that capture the semantic essence of the text. This process typically involves using models like BERT or its variants, which are trained to understand the nuances of language.
Best Practices
- Dimensionality: Choosing the right size for your vectors is a trade-off between computational efficiency and the ability to capture detailed semantic information.
- Model Selection: The choice of model for vectorization should align with your documents’ nature and the level of understanding required.
Methods
- Pre-trained Models: Use models like BERT, RoBERTa, or GPT-3.5 for embedding, choosing based on the language and domain of the documents. For example, SciBERT is optimized for scientific texts.
- Dimensionality: Typical vector sizes range from 256 to 768 dimensions. Higher dimensions capture more detail but require more storage and computational resources.
Examples
- Using Hugging Face Transformers: Load a pre-trained BERT model and vectorize text chunks. The transformers library provides an easy interface for this task.
- Optimization: Apply techniques like Principal Component Analysis (PCA) to reduce vector dimensionality while preserving semantic information.
4. Storing the Embeddings in the Vector Store
After vectorization, these embeddings are stored in a vector database or store optimized for high-speed similarity searches. Technologies like FAISS or Elasticsearch can be employed to manage and retrieve these vectors efficiently.
Efficiency and Scalability
- Indexing: Proper indexing is crucial for quick retrieval. Techniques like quantization can reduce the vector size, improving speed and storage requirements.
- Parallelization: Utilizing distributed computing can significantly enhance retrieval, especially for large datasets.
Technologies
- Vector Stores → Several vector stores are emerging in the market
example:
Milvus is a scalable, open-source vector database optimized for similarity searches. It boasts advanced indexing and a cloud-native design for large-scale applications.
Pinecone: Specializes in ultra-fast vector searches, offering real-time updates and hybrid search capabilities with robust security features for mission-critical uses.
Weaviate: Offers a developer-friendly, AI-native vector database that supports hybrid searches and is designed for scalability and security in AI applications.
Elasticsearch combines text and vector searches for accurate retrieval. It features comprehensive search-building tools and robust access controls for large-scale embedding storage.
Vespa: Used by leading companies for its real-time AI applications support, Vespa excels in vector, lexical, and structured data searches, ensuring scalability and reliability.
Chroma is an open-source, AI-native vector database
PGVector is an open-source PostgreSQL extension that facilitates vector similarity search within Postgres
Implementation Details
- Indexing Strategy: Use a flat index for small datasets or a quantized index for larger datasets to balance accuracy and speed.
- Sharding: Distribute the vector database across multiple machines to scale horizontally as the dataset grows.
5. Repeating the Process for Queries
Vectorize the Question
Just like document chunks, the user’s query is also vectorized using the same model to ensure consistency in representation.
Vectorizing Queries
- Consistency: To maintain semantic alignment, ensure the same vectorization model and parameters are used for both documents and queries.
- Real-time Processing: Implement vectorization as a real-time process, allowing users to submit queries dynamically.
Retrieve Relevant Chunks
The vectorized query is then used to search the vector store for the most semantically similar document chunks. This retrieval is based on similarity metrics like cosine similarity.
Best Practices for Retrieval
- Thresholding: Setting a minimum similarity score can help filter out irrelevant results.
- Diversity: Employing techniques to ensure a diverse set of results can prevent the model from focusing too narrowly on a specific topic area.
Retrieval Mechanics
- K-nearest Neighbors (k-NN) Search: Set an appropriate value for k to retrieve a balanced set of relevant documents. Too few might miss useful information, and too many could dilate the context with noise.
- Scoring and Ranking: Beyond vector similarity, incorporate additional metrics (e.g., document freshness, citations) to rank the retrieved chunks.
6. Integrating with a Large Language Model (LLM)
The retrieved chunks serve as the context or the knowledge base for the LLM to generate a response. This step involves feeding the model both the query and the retrieved documents, allowing it to synthesize the information into a coherent and relevant answer.
Best Practices
- Context Selection: Carefully selecting which parts of the retrieved chunks to present to the LLM can impact the quality of the response.
- Feedback Loops: Incorporating user feedback can help refine the retrieval process, ensuring that the system improves over time.
Feeding Context to LLM
- Selective Integration: Select the most relevant snippets to feed into the LLM from the retrieved chunks. This might involve summarizing or further processing to distil the essence.
- Custom Models: Depending on the application, consider fine-tuning models like GPT-3 on domain-specific data to improve response relevance and accuracy.
Technical Specs
- API Calls: When integrating with services like OpenAI’s GPT-3, manage API call quotas and response times by batching requests or caching frequent queries.
7. Delivering the Answer to the User
Finally, the generated response is presented back to the user. This step might involve post-processing the text to improve readability or formatting the reaction to best suit the user’s needs.
Post-Processing
- Natural Language Generation (NLG): Apply NLG techniques to convert model outputs into user-friendly answers, enhancing readability and coherence.
- Formatting: Tailor the response format to the user interface, whether a chatbot, a search engine, or a voice assistant.
Conclusion
The RAG framework represents a powerful approach to NLP, leveraging the strengths of both retrieval systems and generative models to produce highly relevant and informed responses. Developers can create systems by carefully considering each component of the retrieval process, from document extraction to the final response generation.